Factorization machine examples#
In this notebook we train two Factorization Machines (FMs) on the California Housing dataset, such that the numerical feature embedding vectors are defined by parametric curves. Each feature value is mapped to a point on the curve in the embedding space. One FM is based on B-Spline curves, whereas the other on Legendre polynomial curves.
[1]:
import math
import kagglehub as kh
import matplotlib.pyplot as plt
import numpy as np
import torch
import torch.utils.data as td
from sklearn.compose import make_column_transformer
from sklearn.impute import SimpleImputer
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import OrdinalEncoder, StandardScaler
from torch import nn
import torchcurves as tc
Prepare data#
[2]:
file_path = "housing.csv"
df = kh.dataset_load(
kh.KaggleDatasetAdapter.PANDAS,
"camnugent/california-housing-prices",
file_path
)
Warning: Looks like you're using an outdated `kagglehub` version (installed: 0.3.12), please consider upgrading to the latest version (1.0.0).
[3]:
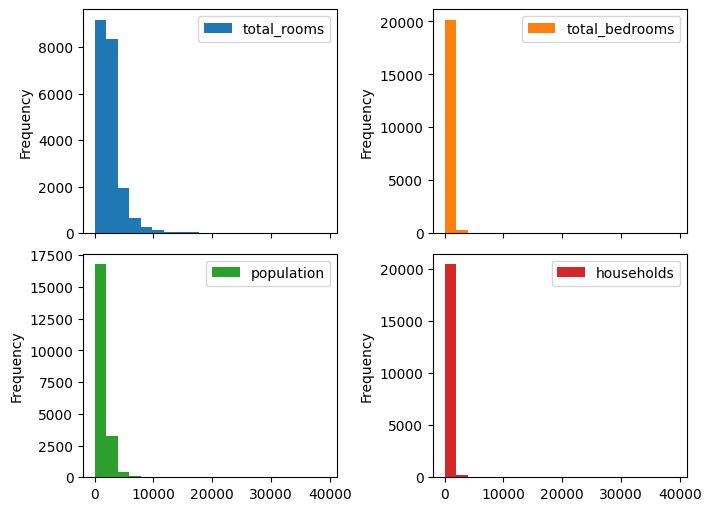
# columns that we know have a very skewed distribution
skewed_columns = ['total_rooms', 'total_bedrooms', 'population', 'households']
df[skewed_columns].plot.hist(
bins=20, subplots=True, layout=(2, 2), figsize=(7, 5)
)
plt.gcf().set_layout_engine('constrained')
[4]:
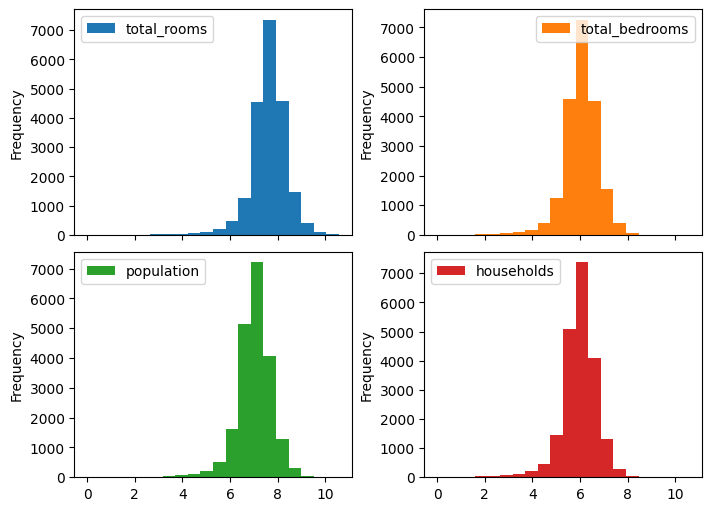
# apply a log1p transformation and plot the new distribution
df.loc[:, skewed_columns] = df[skewed_columns].apply(np.log)
df[skewed_columns].plot.hist(
bins=20, subplots=True, layout=(2, 2), figsize=(7, 5)
)
plt.gcf().set_layout_engine('constrained')
[5]:
# define numerical, categorical, and label cols
num_cols = [
'longitude',
'latitude',
'housing_median_age',
'total_rooms',
'total_bedrooms',
'population',
'households',
'median_income'
]
cat_cols = ['ocean_proximity']
label_col = 'median_house_value'
[6]:
train_df = df.sample(frac=0.8, random_state=2025)
test_df = df.drop(train_df.index)
Preprocess data#
[7]:
X_train, y_train = train_df.drop(label_col, axis=1), train_df[[label_col]]
X_test, y_test = test_df.drop(label_col, axis=1), test_df[[label_col]]
[8]:
feat_preprocessor = make_column_transformer(
(OrdinalEncoder(), cat_cols), # categorical: ordinal encode
(make_pipeline(
SimpleImputer(),
StandardScaler()
), num_cols), # numerical: impute then scale
verbose_feature_names_out=False
).set_output(transform='pandas')
label_preprocessor = StandardScaler()
[9]:
X_train_pp = feat_preprocessor.fit_transform(X_train)
X_test_pp = feat_preprocessor.transform(X_test)
y_train_pp = label_preprocessor.fit_transform(y_train)
y_test_pp = label_preprocessor.transform(y_test)
[10]:
X_train_cat = X_train_pp[cat_cols].values
X_train_num = X_train_pp[num_cols].values
X_test_cat = X_test_pp[cat_cols].values
X_test_num = X_test_pp[num_cols].values
[11]:
num_cat_features = [
len(cats) for cats in feat_preprocessor['ordinalencoder'].categories_
]
Train and evaluate models#
Define modules#
[12]:
class FM(nn.Module):
"""Base class for factorization machine modules with numerical embeddings.
Args:
num_cont_features (int): the number of continuous numerical features.
Each feature is associated with a curve in the embedding space.
num_cat_features (list[int]): The number of categorical features in each
categorical field. Each categorical feature has its
own embedding vector.
emb_dim (int): the dimension of the factorization machine embedding
vectors.
num_emb_ctor (Callable[int, int, **kwargs]): a function that constructs
the curve objects that serve as the numerical embeddings. We will
use this flexibility to test both Legendre and Spline embeddings.
num_emb_kwargs (dict): keyword arguments to pass to ``num_emb_ctor``.
"""
def __init__(self, num_cont_features, num_cat_features, emb_dim, num_emb_ctor, num_emb_kwargs):
super().__init__()
self.bias = nn.Parameter(torch.tensor(0.))
# continuous features represented by curves
self.pwise_cont_emb = num_emb_ctor(
num_cont_features, emb_dim, **num_emb_kwargs
)
self.linear_cont_emb = num_emb_ctor(
num_cont_features, 1, **num_emb_kwargs
)
# categorical features represented by regular embeddings
total_num_cat_features = sum(num_cat_features)
self.pwise_cat_emb = nn.Embedding(total_num_cat_features, emb_dim)
self.linear_cat_emb = nn.Embedding(total_num_cat_features, 1)
# assume categorical features are ordinally-encoded for each column
# separately, so to index one big embedding table we need an offset
# per column.
cat_feature_offsets = torch.cumsum(
torch.as_tensor([0, *num_cat_features]), dim=-1
)
cat_feature_offsets = cat_feature_offsets[:-1]
self.register_buffer("cat_feature_offsets", cat_feature_offsets)
def forward(self, num, cat):
# get embeddings and linear terms for numerical features
num_emb = self.pwise_cont_emb(num)
num_lin = self.linear_cont_emb(num)
# get embeddings and linear term for categorical features
offset_cat = cat + self.cat_feature_offsets
cat_emb = self.pwise_cat_emb(offset_cat)
cat_lin = self.linear_cat_emb(offset_cat)
# compute pairwise interactions between all embeddings using
# the square_of_sum - sum_of_square trick from the FM paper
# by Rendle et. al. (2010).
emb = torch.cat((num_emb, cat_emb), axis=-2)
sum_of_sq = emb.square().sum(dim=(-2, -1))
sq_of_sum = emb.sum(dim=(-2, -1)).square()
pairwise_term = (sq_of_sum - sum_of_sq) / 2.
# compute the linear term for both categorical and numerical features
linear_term = num_lin.sum(dim=(-2, -1)) + cat_lin.sum(dim=(-2, -1))
return pairwise_term + linear_term + self.bias
[13]:
class BSplineFM(FM):
"""An FM with `real.rational` B-Spline embeddings."""
def __init__(self, num_cont_features, num_cat_features, emb_dim, num_coefs=10):
super().__init__(
num_cont_features,
num_cat_features,
emb_dim,
tc.BSplineCurve,
num_emb_kwargs={"knots_config": num_coefs, "input_map": "real.rational"},
)
class LegendreFM(FM):
"""An FM with `real.rational` Legendre curve embeddings."""
def __init__(self, num_cont_features, num_cat_features, emb_dim, num_coefs=10):
super().__init__(
num_cont_features,
num_cat_features,
emb_dim,
tc.LegendreCurve,
num_emb_kwargs={"degree": num_coefs - 1, "input_map": "real.rational"},
)
Model training logic#
[14]:
device = "cuda" if torch.cuda.is_available() else "cpu"
/home/alex/git/torchcurves/.venv/lib/python3.12/site-packages/torch/cuda/__init__.py:174: UserWarning: CUDA initialization: The NVIDIA driver on your system is too old (found version 11040). Please update your GPU driver by downloading and installing a new version from the URL: http://www.nvidia.com/Download/index.aspx Alternatively, go to: https://pytorch.org to install a PyTorch version that has been compiled with your version of the CUDA driver. (Triggered internally at /pytorch/c10/cuda/CUDAFunctions.cpp:109.)
return torch._C._cuda_getDeviceCount() > 0
[15]:
train_ds = td.TensorDataset(
torch.as_tensor(X_train_num, dtype=torch.float32),
torch.as_tensor(X_train_cat, dtype=torch.int32),
torch.as_tensor(y_train_pp, dtype=torch.float32)
)
eval_ds = td.TensorDataset(
torch.as_tensor(X_test_num, dtype=torch.float32),
torch.as_tensor(X_test_cat, dtype=torch.int32),
torch.as_tensor(y_test_pp, dtype=torch.float32)
)
[16]:
# we aren't tuning hyperparameters for each model, so we're conservative - many
# epochs with a small step-size
num_epochs = 200
lr = 1e-4
print_every = 25 # print progress every N epochs
emb_dim = 10 # factorization machine embedding dimension
batch_size = 32 # training batch size
train_set_size = len(X_train_pp)
test_set_size = len(X_test_pp)
[17]:
def train_epoch(model, optim, criterion, train_dl):
"""Run a standard PyTorch training epoch."""
tr_loss = 0.
for xnum, xcat, yb in train_dl:
xnum = xnum.to(device)
xcat = xcat.to(device)
yb = yb.to(device)
pred = model(xnum, xcat)
loss = criterion(yb.squeeze(), pred)
optim.zero_grad()
loss.backward()
optim.step()
tr_loss += loss * torch.numel(yb)
return tr_loss.item() / train_set_size
@torch.no_grad
def eval_epoch(model, eval_criterion, eval_dl):
"""Run a standard evaluation epoch.
Scales the model's output to the original unit to compute RMSE in terms
of dollars, instead of in terms of standardized labels.
"""
eval_total_error = 0.
for xnum, xcat, yb in eval_dl:
# predict
pred = model(xnum.to(device), xcat.to(device))
# compute label and prediction in terms of dollars
label_orig = label_preprocessor.inverse_transform(yb.view(-1, 1))
pred_orig = label_preprocessor.inverse_transform(pred.cpu().view(-1, 1))
# compute loss on the original labels
loss = eval_criterion(
torch.as_tensor(label_orig, device=device, dtype=torch.float32),
torch.as_tensor(pred_orig, device=device, dtype=torch.float32)
)
eval_total_error += loss * torch.numel(yb)
return eval_total_error.item() / test_set_size
[18]:
def train_eval_model(
name, model: nn.Module, batch_size: int,
print_progress=True, **optim_kwargs
):
"""Run a standard training loop for several epochs."""
model = model.to(device)
optim = torch.optim.AdamW(model.parameters(), **optim_kwargs)
criterion = nn.MSELoss()
train_dl = td.DataLoader(train_ds, batch_size=batch_size, shuffle=True)
eval_dl = td.DataLoader(eval_ds, batch_size=128)
for epoch in range(1, num_epochs + 1):
train_loss = train_epoch(model, optim, criterion, train_dl)
eval_loss = eval_epoch(model, criterion, eval_dl)
eval_rmse = math.sqrt(eval_loss)
if print_progress and (epoch % print_every == 0 or epoch == num_epochs):
print(f'[{name}] Epoch {epoch}, tr loss = {train_loss:.4f}, eval RMSE = {eval_rmse:.2f}')
return model
Run experiments#
[19]:
bspline_model = train_eval_model(
"BSpline",
BSplineFM(len(num_cols), num_cat_features, emb_dim),
lr=lr, weight_decay=1e-6, batch_size=batch_size
)
[BSpline] Epoch 25, tr loss = 0.3618, eval RMSE = 67840.35
[BSpline] Epoch 50, tr loss = 0.2980, eval RMSE = 62150.61
[BSpline] Epoch 75, tr loss = 0.2848, eval RMSE = 61247.68
[BSpline] Epoch 100, tr loss = 0.2797, eval RMSE = 60420.26
[BSpline] Epoch 125, tr loss = 0.2768, eval RMSE = 59821.41
[BSpline] Epoch 150, tr loss = 0.2745, eval RMSE = 60103.72
[BSpline] Epoch 175, tr loss = 0.2725, eval RMSE = 59293.71
[BSpline] Epoch 200, tr loss = 0.2710, eval RMSE = 59205.04
[21]:
hires_bspline_model = train_eval_model(
"BSpline-HiRes",
BSplineFM(len(num_cols), num_cat_features, emb_dim, num_coefs=50),
lr=lr, weight_decay=1e-7, batch_size=batch_size
)
[BSpline-HiRes] Epoch 25, tr loss = 0.2570, eval RMSE = 57707.76
[BSpline-HiRes] Epoch 50, tr loss = 0.2471, eval RMSE = 56812.46
[BSpline-HiRes] Epoch 75, tr loss = 0.2429, eval RMSE = 56291.40
[BSpline-HiRes] Epoch 100, tr loss = 0.2407, eval RMSE = 55888.36
[BSpline-HiRes] Epoch 125, tr loss = 0.2383, eval RMSE = 55983.25
[BSpline-HiRes] Epoch 150, tr loss = 0.2362, eval RMSE = 55561.15
[BSpline-HiRes] Epoch 175, tr loss = 0.2338, eval RMSE = 55684.88
[BSpline-HiRes] Epoch 200, tr loss = 0.2322, eval RMSE = 55159.26
[22]:
legendre_model = train_eval_model(
"Legendre",
LegendreFM(len(num_cols), num_cat_features, emb_dim),
lr=lr, weight_decay=1e-6, batch_size=batch_size
)
[Legendre] Epoch 25, tr loss = 0.3089, eval RMSE = 62332.28
[Legendre] Epoch 50, tr loss = 0.2892, eval RMSE = 61275.94
[Legendre] Epoch 75, tr loss = 0.2853, eval RMSE = 60274.15
[Legendre] Epoch 100, tr loss = 0.2829, eval RMSE = 60224.15
[Legendre] Epoch 125, tr loss = 0.2814, eval RMSE = 59990.27
[Legendre] Epoch 150, tr loss = 0.2796, eval RMSE = 60553.25
[Legendre] Epoch 175, tr loss = 0.2785, eval RMSE = 59866.91
[Legendre] Epoch 200, tr loss = 0.2769, eval RMSE = 59727.98
[23]:
highdeg_legendre_model = train_eval_model(
"Legendre-HiDeg",
LegendreFM(len(num_cols), num_cat_features, emb_dim, num_coefs=50),
lr=lr, weight_decay=1e-7, batch_size=batch_size
)
[Legendre-HiDeg] Epoch 25, tr loss = 0.2477, eval RMSE = 57568.71
[Legendre-HiDeg] Epoch 50, tr loss = 0.2280, eval RMSE = 54972.16
[Legendre-HiDeg] Epoch 75, tr loss = 0.2204, eval RMSE = 53762.76
[Legendre-HiDeg] Epoch 100, tr loss = 0.2151, eval RMSE = 53314.58
[Legendre-HiDeg] Epoch 125, tr loss = 0.2113, eval RMSE = 53115.67
[Legendre-HiDeg] Epoch 150, tr loss = 0.2075, eval RMSE = 52705.36
[Legendre-HiDeg] Epoch 175, tr loss = 0.2026, eval RMSE = 52546.22
[Legendre-HiDeg] Epoch 200, tr loss = 0.1985, eval RMSE = 52489.22